

Streaming Data Pipelines with Striim + DuckDB
Streaming Data Pipelines with Striim + DuckDB

Big thanks to Striim for getting me a preview of their new developer experience and sponsoring this post.

Last month I got a sneak preview of Striim’s new developer experience that makes it easy to get started with CDC using BigQuery or Snowflake. If you missed my thread about that, check it out. In this post, I’ll look at how you can leverage Striim, Parquet, and DuckDB for real-time data ingestion with fast data analysis.
Data pipelines have traditionally been batch, and batch pipelines are usually easier to reason about. Data comes in once a day. I run all my transformations and load them sometime between 12:01 AM and 7 AM UTC (or was it PT? Timezones are hard.) Views and tables get updated, people look at data from yesterday, they get the answers to all their questions, and life is good. Life is simple.
Unfortunately: the good old days are dead. Now we run operational workflows off data constantly fed into the data warehouse. We need to reduce the lag of all the various components that ingest, digest, transform, and reform our data as much as possible. For example, we have personalized workflows that send automated emails to prospects and customers who expect us to understand only every interaction they’ve had with us but also anticipate every human desire they could conceivably have in the next fifteen minutes.
We’ve started pushing batch to the limits of streaming. Some of these batch tools can run as often as every 5 minutes, pushing the boundaries of what is and isn’t streaming anymore.
This is what got me interested in the streaming and CDC space in the first place. I wanted to know if there was a better way. After a dizzying stroll down Debezium Lane, and a confusing jaunt through Kafka Caverns, I received a nice demo from the fine folks at Striim.
Striim is an enterprise-grade CDC platform, and I am but a lowly developer with toy examples, and it works just as well for me. For my first attempt in the tweet above, I set up a simple Postgres instance, piped data into it, and watched as Striim fed my BigQuery tables with change capture data every few seconds.
But BigQuery is old news. Today, I wanted to see if I could get our lord and savior, DuckDB, to work with Striim. The setup was simple: use a GCP Writer to save streaming data to Parquet. Then, use DuckDB’s HTTPFS extension to read data from Parquet files in bulk. Write queries. Enjoy streaming.
Let’s dive in.
Striim Setup
I decided to use one of the built-in data generators to get started quickly. These data generators are great for sketching out ideas since they let you avoid the messy parts of connecting data systems, such as permissions and IP allow-lists.
The ContinousGenerator can be set to various types of throughput. Low Throughput sends about ten messages per second, Medium for hundreds per second, or Spike for variable traffic with high spikes which can be handy for testing the resiliency of your pipelines.
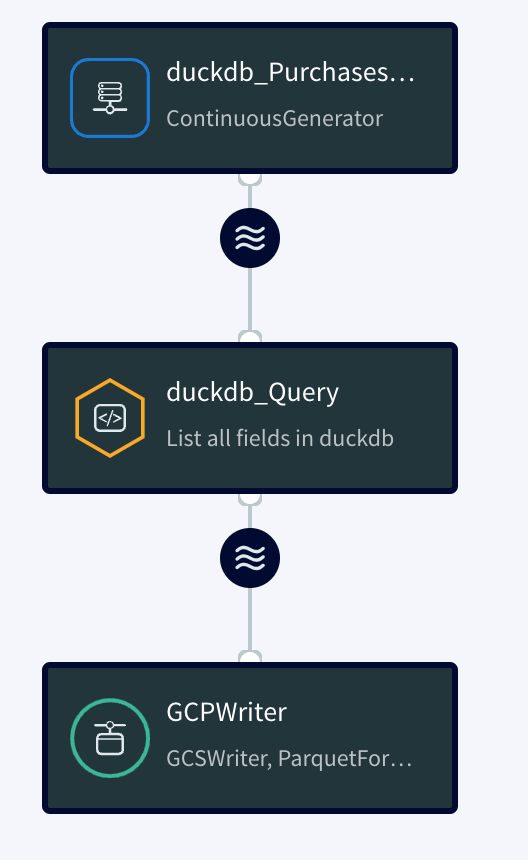
Next up, I used a Query cell, which operates on an incoming stream and allows you to do transformations as data is produced. This can save lots of expensive compute in your warehouse by shifting the transformations left, closer to the data source. You can also do data-masking as data arrives, to make staying compliance easier. I wrote a simple query that takes the generated data, masks sensitive information, and outputs the results to a GDPR stream.
Finally, to be able to analyze this data in DuckDB, I elected to write the data in Parquet format to Google Cloud Storage, although S3 would also work just as well. To do that, I used the GCP Writer Target. After creating a Service Account in Google Cloud, I setup a few basic settings such as the path to the bucket and format I’d like the files saved in.
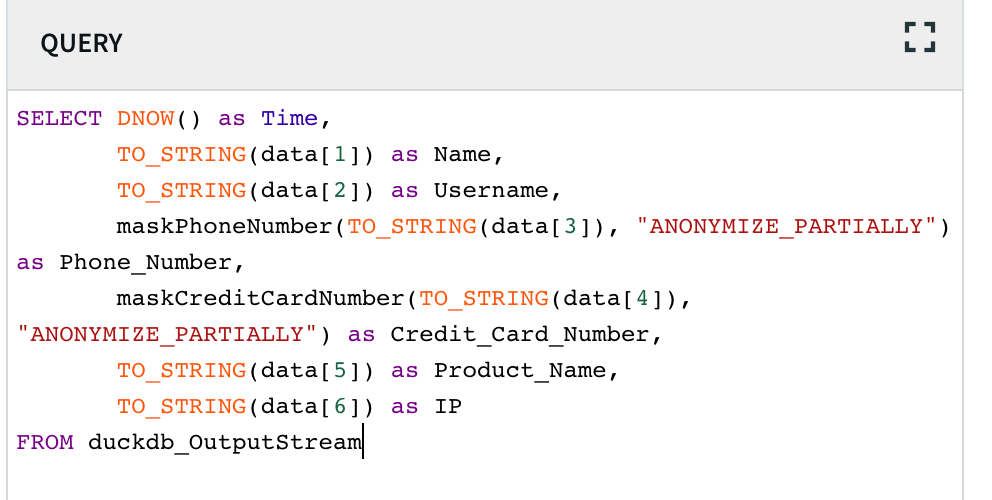
One setting to be aware of is the Upload Policy, which determines how frequently (and conversely, how large) the files are. Finding a good balance here is important, as too many files or too few can both hinder performance.
I set the Upload Policy to write every 100,000 events or every 1 minute. I set the ParquetFormatter as the output option.
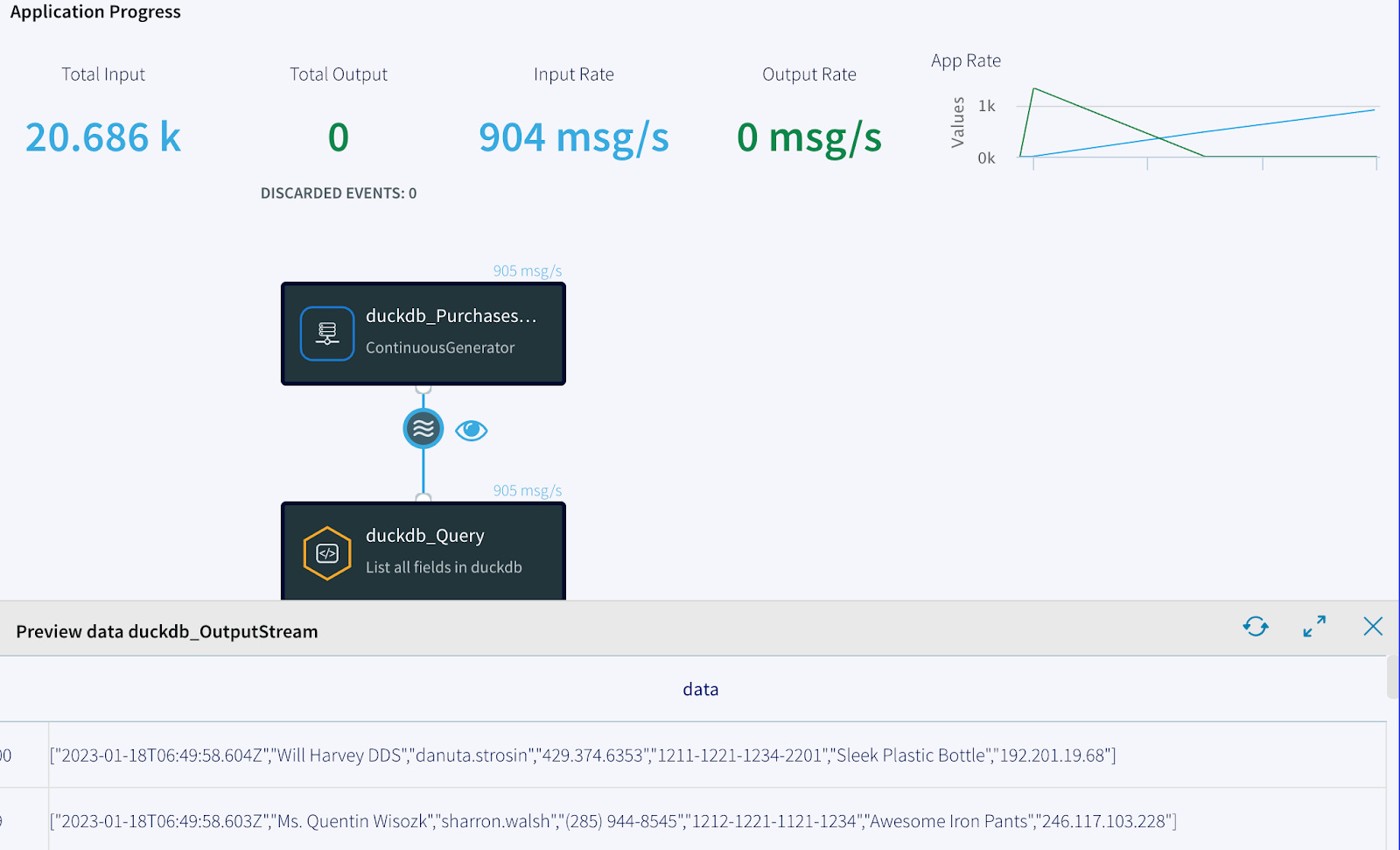
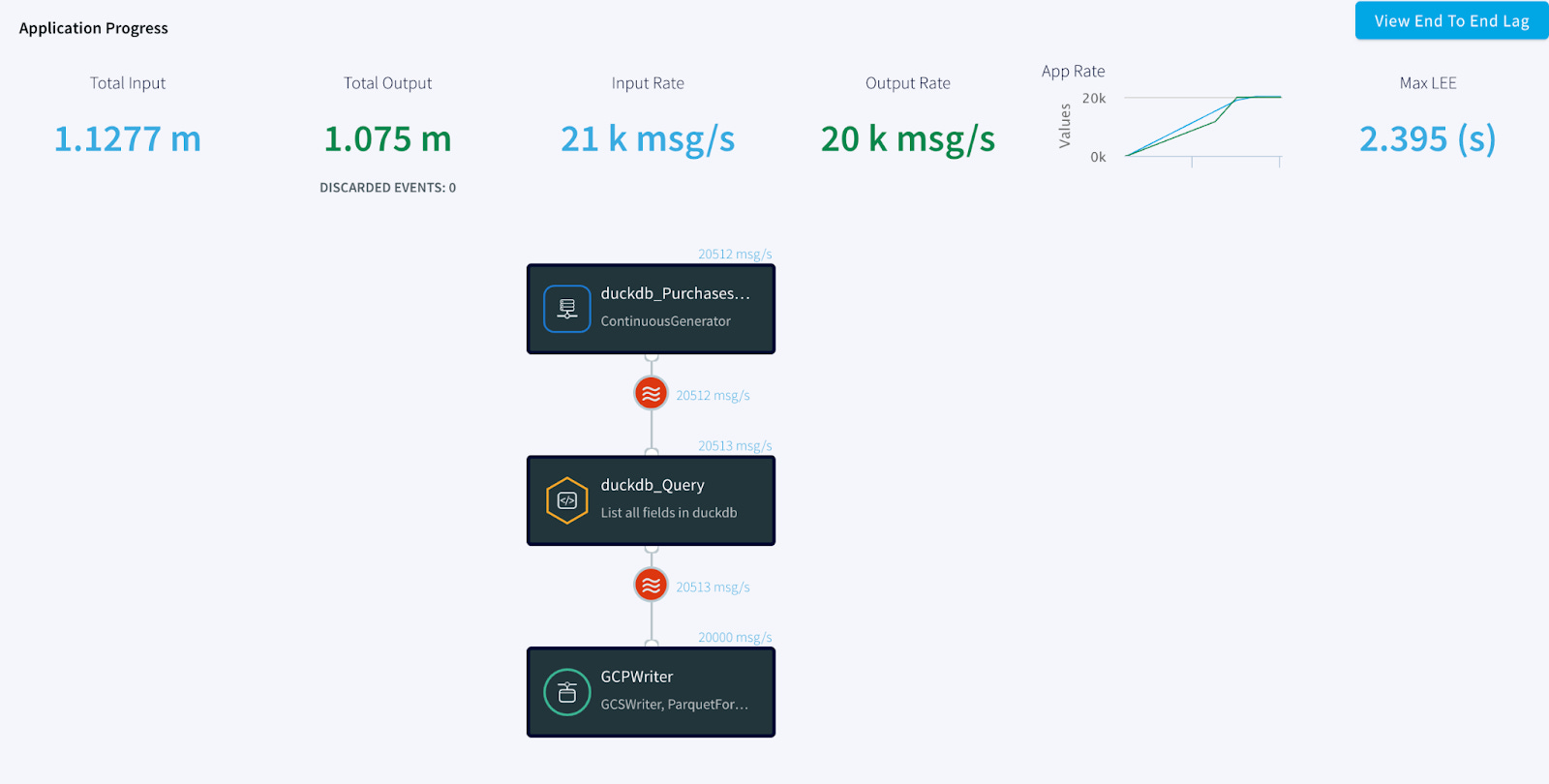
With the setup complete, all that is needed is for the app to be deployed and started. You even have a preview feature to watch data as it is fed through the system. You can see I’m fetching about 900 messages every second, and after about a minute the data will write to GCP.
What’s neat is that Striim even displays the total End to End Lag so you can have insight into how delayed your pipelines are. In my case, the lag was about 30 seconds from creation to write.
After running for a while, the Parquet files are loaded in GCP and now it’s time to analyze the results with DuckDB.
Analyze with DuckDB
There are many ways to use DuckDB given that it’s a small portable binary. The CLI is a great place for simple prototyping but I prefer using Datagrip for writing queries.
After creating a new DuckDB connection and enabling single-session mode, I added a small startup script to ensure that every time I connect to DuckDB my GCP credentials are entered.

The docs on setting up S3 or GCS access are pretty straightforward. A few simple SET commands and then you’re ready to query!
INSTALL httpfs;
LOAD httpfs;
SET s3_endpoint='storage.googleapis.com';
SET s3_access_key_id='MY_ACCESS_KEY';
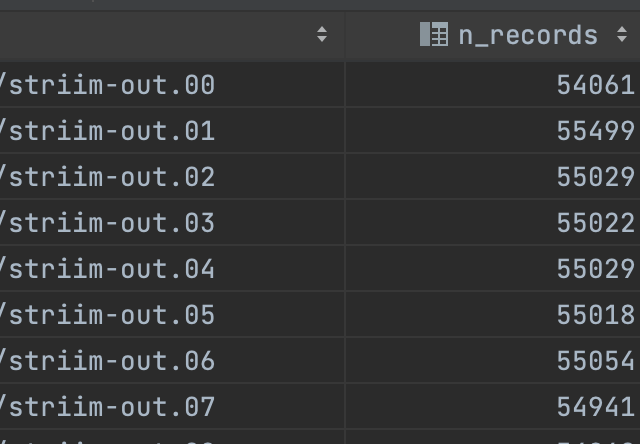
SET s3_secret_access_key='MY_SECRET';To start, I ran a simple query to see how many records we have in each file. By using the filename=TRUE command, DuckDB returns the filename as a column in the table, which I use for aggregation.
SELECT
filename,
COUNT(1) AS n_records
FROM parquet_scan('s3://my-duckdb-bucket/striim-out.*', filename=TRUE)
GROUP BY filename
ORDER BY 1;In about 7 seconds, DuckDB scanned 760,000 records across 14 files with 55,000 records each to generate a count of records by file. And the best part is there’s no Spark cluster to maintain. You can see below that using the filename to do a group by makes it easy to get a sense of how many records were written in each file.
We can even do fast text processing. In 6 seconds, I can categorize all products by whether they have Heavy or Lightweight in their name and aggregate across both dimensions.
SELECT
product_name LIKE '%Lightweight%' AS is_lightweight,
product_name LIKE '%Heavy%' AS is_heavy,
COUNT(1) AS count_products
FROM parquet_scan('s3://my-duckdb-bucket/striim-out.*')
GROUP BY 1, 2;
The best part is this data is constantly updated by Striim. Every minute a new batch of 55,000 records arrives.
That was fun, but we needed to go faster. Just for fun, I cranked up the generator to see how it would handle a higher rate and set the Upload Limit to 25,000 records per file. I easily hit 20,000 messages per second, and the end-to-end lag was just a few seconds. Striim had no problem with the throughput. In just a few minutes, I had 60 Parquet files ready for DuckDB to process.
With now 60 files to process, DuckDB took just under 30 seconds to count every record in every file. The product name query now took 23 seconds on 1.45 million records.

As one final test, I decided to push some regex and aggregates down to see the impact on performance, and DuckDB held up well. This query took under a minute to query all 1.45 million records, and I didn’t have to store a single file locally. (And if you were wondering, the average of the last 4 digits of a phone number is 5001).
SELECT
date_trunc('minute', CAST(TIME AS TIMESTAMP)) AS DATE,
avg(CAST(regexp_extract(Phone_Number, '\d+') AS NUMERIC)) AS avg_number
FROM parquet_scan('s3://my-duckdb-bucket/striim-out.*')
GROUP BY 1Wrapping Up
I hope this was a helpful exploration of how you can use Striim and DuckDB to process real-time analytic queries quickly and easily. Gone are the days of Kafka, Zookeeper and Debezium. In less than 30 minutes you can get a CDC stream setup, write to a cloud bucket location, and query with DuckDB for blazing-fast analytics.
If you want to give Striim a try, you can sign up here with my referral code tAlaDngxjQ.